Thinking virtual agents. The source of their wisdom, and novel ways to visualise it into migration-related graphs.
Nowadays Virtual Agents such as chatbots are used in a daily basis and we are used in a way to have them in our lives. The WELCOME project is using this technology to develop an Application that can help migrants and refugees to adapt better into their hosting society. But, how does this technology work and how can we use it to make the lives of migrants and refugees easier? This article explores how virtual agents can change the game in this field.
Amalia Georgoudi, Grigoris Tzionis, Gerasimos Antzoulatos, Dimos Dioudis, Thanassis Mavropoulos (CERTH) Thessaloniki (Greece),
Communication is a vital part of daily life. We talk with our friends, co-workers, and even random people about a variety of topics and for a variety of reasons. Many science fiction stories, movies, and TV shows include people conversing with computers in the same way they do with humans. Virtual agents can be used for that purpose.
A virtual agent is a software application that uses a combination of pre-programmed rules and conversational artificial intelligence to give basic assistance or services to humans. Chatbots, voice bots, and even interactive voice response systems are all examples of virtual agents. It can be helpful to think of a virtual agent as a digital assistant. There are many benefits in using them. First of all, a virtual agent provides services and support 24/7. It improves the experience and satisfaction of a person, by reducing the first response time and providing personalised answers. Furthermore, utilising virtual agents, reduces pressure on human assistants by automating repetitive tasks. Staff is no longer needed to spend time on simple, straightforward issues, resulting in a reduction in the number of requests they must address. They will be able to devote more time to more complex issues.
A virtual agent’s initial step is to transform human speech into text. Although it is commonly thought to be simple for native speakers of a language, converting speech to text is a difficult undertaking. Aside from the written message, the audio signal is affected from channel parameters (e.g., microphone), non-speech events such as background noise or coughing, language/dialect differences, and speaker characteristics (e.g., accent, gender, age, identification). Perfect formulation can be seen only in written texts because people make many hesitations, false starts, repairs, and ungrammatical constructs when they talk, and these cannot be undone.
Moreover, in order to support natural human-machine communication, virtual agents exploit Machine Learning[1] (ML) and Natural Language Processing[2] (NLP) technologies. Machine Learning is a sort of Artificial Intelligence (AI) that focuses on problem solving and helps virtual agents to improve their answers and interactions, while Natural Language Processing focuses on language analysis, which can assist agents in better understanding what users are looking for and identifying the appropriate knowledge to provide. Yet, agents cannot simply predict the information users are looking for. Their insight lies on knowledge bases, which can be used to interpret existing data and infer new facts. Knowledge bases, represented with the use of semantic web languages, such as RDF[3](s) and OWL[4], allow for a fluent representation of various types of data and content using data schemata called ontologies.
What are Ontologies?
An ontology is a formal and clear definition of a commonly accepted formulation of certain domains of interest and is considered as a structured framework for organising information. By defining a common vocabulary, ontologies enable sharing and reusing knowledge as well as adding new knowledge for a specific domain. The atomic data entity of an ontology in the semantic world is called a triple, which is a statement linking an object to another or to a literal via a predicate. Each triple consists of a subject, a predicate, and an object (Figure 1). A collection of such statements forms a graph of facts where the subject and object are the nodes of the graph while the predicates are the edges between them.

Ontologies are constituted of explicitly defined Individuals (instances of objects), classes, characteristics, and relations, as well as restrictions, rules, and axioms. Classes are the main element of an ontology and are used to describe a domain’s concepts. Properties are used to describe feature attributes. Furthermore, an ontology has instances of classes and relationships between those instances.
The WELCOME Ontology
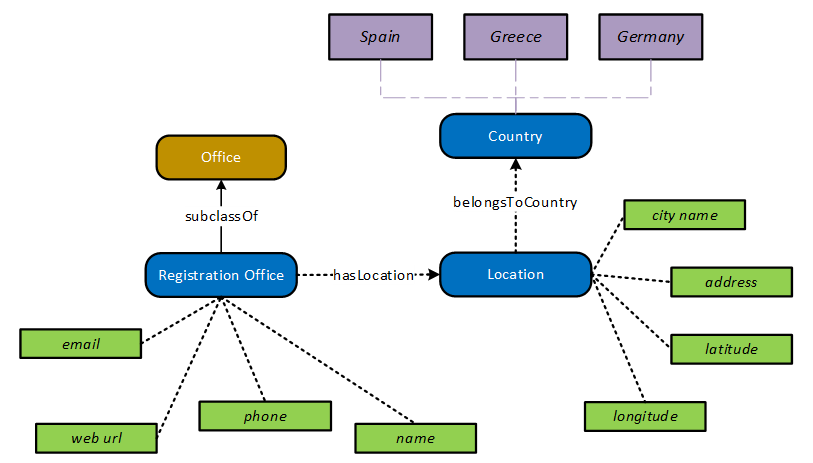
The following figure (Figure 2) represents classes, taken from the WELCOME ontology, along with their properties. In particular, the figure presents the class Registration Office which is a subclass of the class Office. A registration office in the WELCOME ontology can be described by several data properties that can capture the office name, email, web url and phone number. In addition, each entity of the class registration office can be linked to an entity of the class Location that can also be described by several data properties. More specifically, each location is described by a city name, an address, a set of latitude and longitude coordinates and belongs to an entity o the class Country, whose instances are the three WELCOME pilot locations, namely Spain, Greece, and Germany.
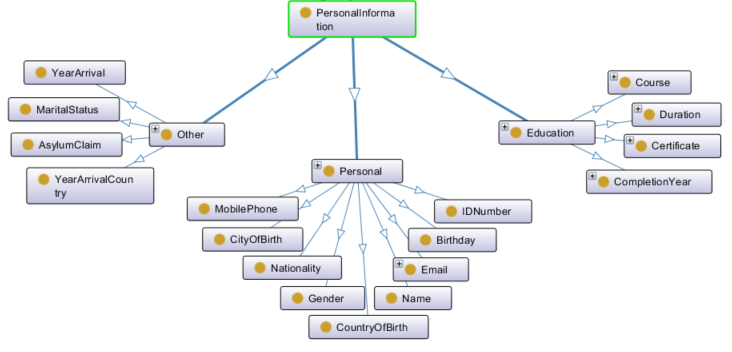
Another example from the WELCOME ontology is shown in Figure 3. The class Personal Information describes a TCN’s personal profile. Personal, Education and Other are subclasses of Personal Information class. Personal has classes that provide information for birthday, city and country of birth, email, name, surname, nationality, gender, etc. Education class contains information about studies, certificates, and language courses performance. The class Other has more personal information such as marital status, arrival year and arrival country. Additionally, the stored personal profile information includes each user’s performance in language teaching activities and minigames.
One of the key features of ontologies is that, by having the essential hierarchy of classes and relationships between them built into them, they enable semantic reasoning i.e., the derivation of implicit knowledge, hidden into metadata, as well as the discovery of inferences based on asserted information. In the context of the WELCOME project, information captured by the WELCOME ontology can also be integrated into interactive visual representations. Such visualisations focus on analytical reasoning techniques and enable authority users to gain greater insights that will directly support their decision making and planning. The following section provides more information on the visual analytics technologies that were used in WELCOME.
Visual Analytics technologies
Visual analytics (VA) is a way of discovering and understanding patterns in large and heterogeneous datasets via visual interpretation. It is an emerging field, which blends methods of statistics, data mining, cognitive science along with visualisation tools, enabling anyone to shift through, analyse, display, and finally understand complex concepts and relationships that are “hidden” in data. Hence, current trends in Visual Analytics involve “humans in the loop”[5], in the sense that effective delegation of perceptive skills, cognitive reasoning and domain knowledge on the human side, coupled with capabilities of machines in powerful computational data management and analytics, enhance the generation and visual representation of new knowledge. Therefore, models that integrate the interplay between machines and humans have been proposed, aiming to foster effective collaboration between them and generate new knowledge, supporting the decision-making processes.
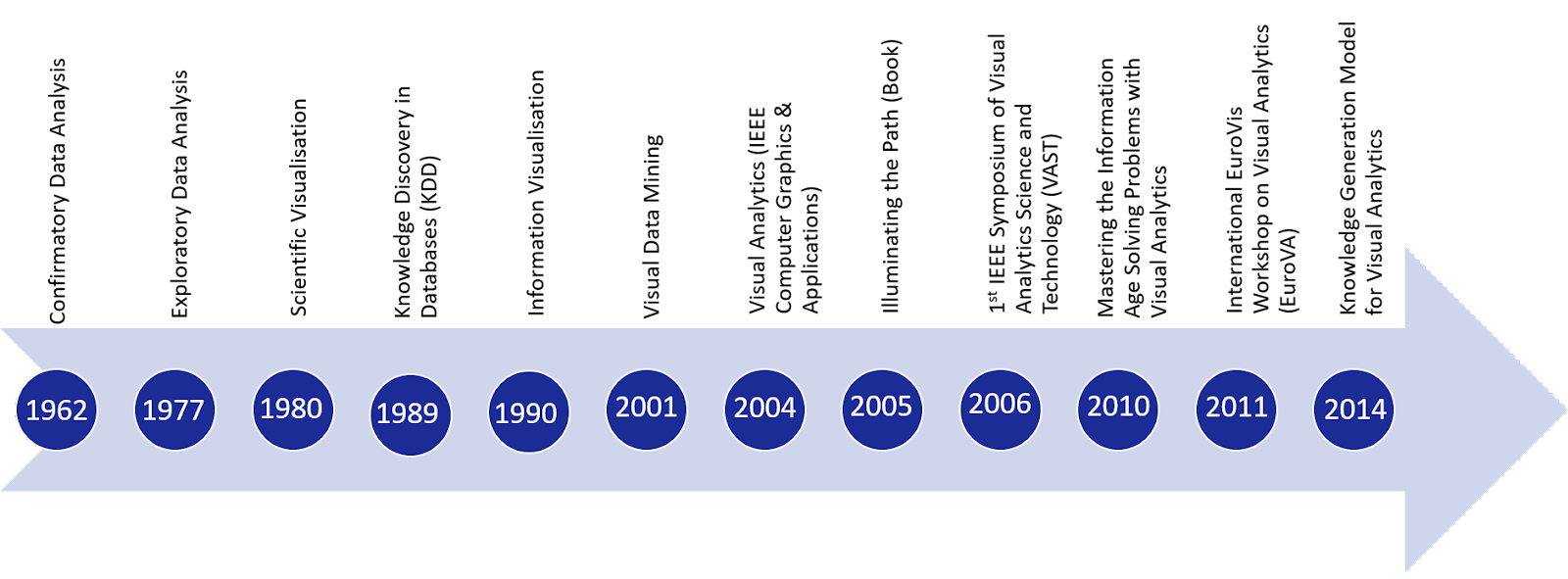
History of Visual Analytics: Statistical and data analysis techniques have been developed independently from visualisations and interactive approaches[6]. However, as data volumes grow dramatically in a wide range of scientific fields, the need for more intuitive and comprehend analytical tools leads to visualisations and charts in order to illustrate descriptive statistics results over the data. In Figure 4, the key points of the evolution of the Visual Analytics are illustrated, focusing on the main events and major aspects of VA development.
To better illustrate the importance of VA, a WELCOME-inspired example is provided in the next section.
Visual Analytics in WELCOME
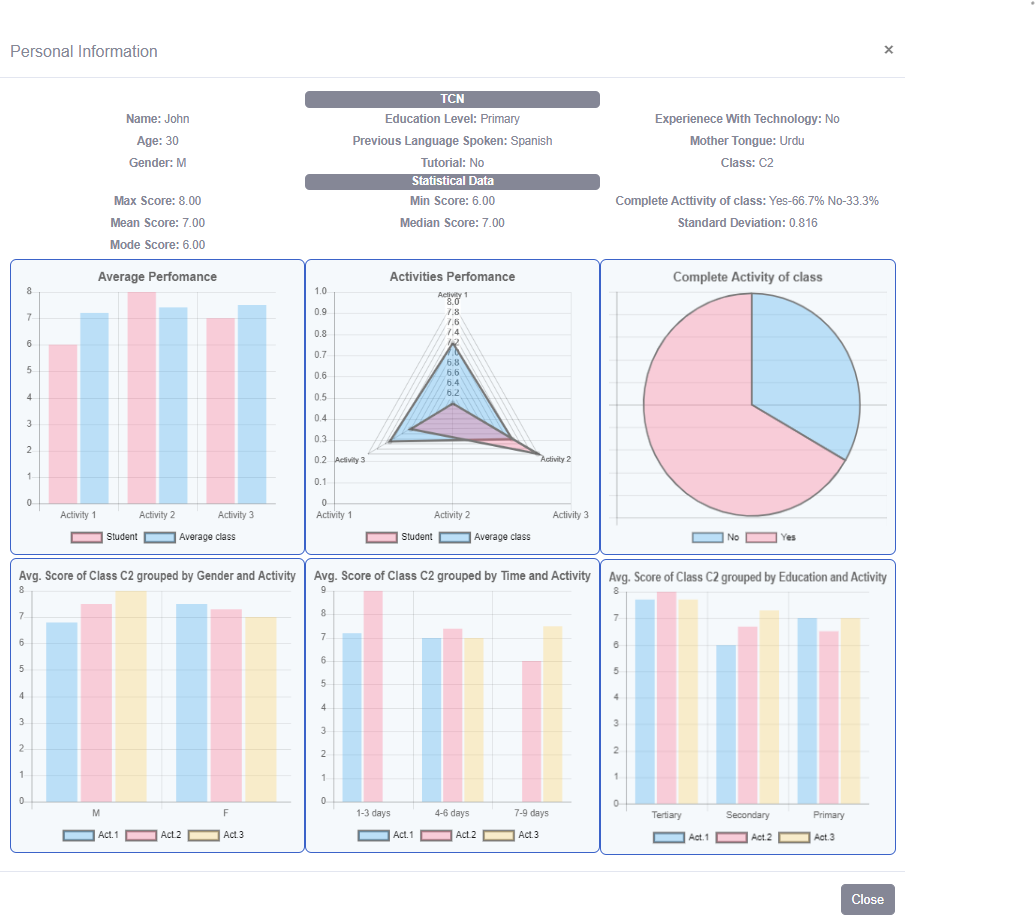
WELCOME provides decision support environments, materialised in the form of a component called Visual Analytics Component (VAC). In its current form and in order to fulfil its role, the VAC provides easy to use front-end user interfaces, capable of offering visualisations which relate to learning and legal analytics outcomes generated by collected data. In the first case, the goal is the recognition and capitalisation of patterns within the characteristics of a Third Country National (TCN) to help Authority and NGO users build the optimal learning paths, depending on the TCN needs and performance (see Figure 5).
Additionally, the VAC may provide useful information and general correlations related to end-user demographics or app usage preferences (see Figure 6). As data play an important role in the process of decision-making and policy design, a qualitative approach may not be enough to plan and implement actions or interventions. However, the quantitative techniques do allow stakeholders to have a clearer picture of the current situation based on the numbers and characteristics of a specific target group. These allow them to intervene in an advocacy level (e.g. policy changes) through the development of horizontal and vertical information, ultimately oriented to the defence of vulnerable populations.
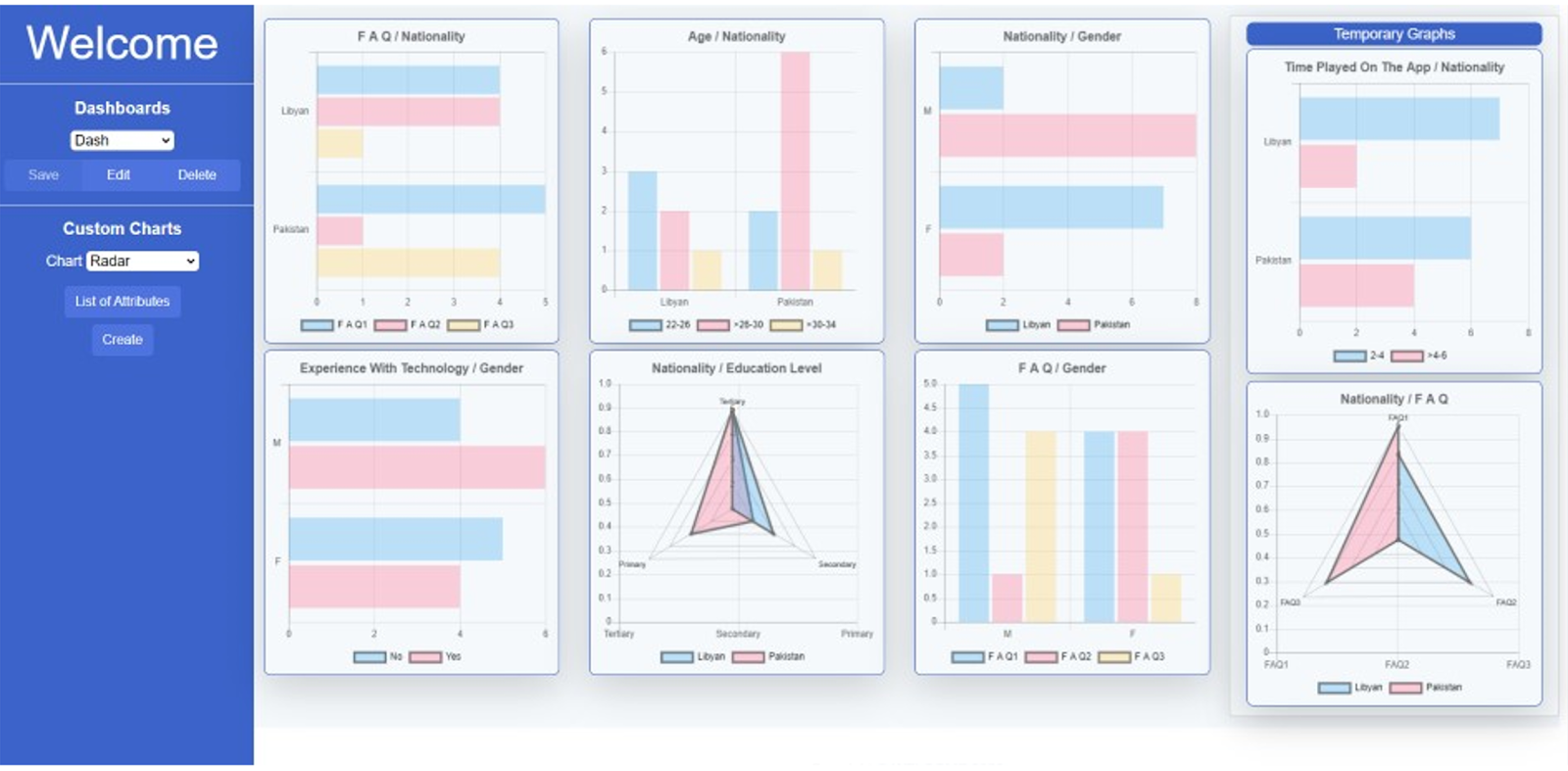
In conclusion, this article has provided an overview of how semantics-conscious virtual agents may be used in migration-related scenarios. By utilising graph-based methods, related with migration, WELCOME project’s virtual agent is able to request and provide important information to TCNs, which is then leveraged by Authorities and NGOs to assist the former. Its source of knowledge is based on a specially designed ontology, which can be populated with useful information for the TCNs, such as available registration offices, and users’ profiles. Moreover, in order for the Authorities/NGOs tο easily understand the information and the broad correlations included in the welcome ontology, the need arose for everything to be captured through interactive visual representations. For this reason, a user-friendly interface was developed, the VAC, which in its current form provides novel visualisations of language learning and legal analytics conclusions, produced from gathered data. As a result of this collaborative effort, the WELCOME project provides new, innovative and personalised digital solutions, that can benefit both local societies and migrants alike.
References:
[1] Badillo, S., Banfai, B., Birzele, F., Davydov, I. I., Hutchinson, L., Kam‐Thong, T., ... & Zhang, J. D. (2020). An introduction to machine learning. Clinical Pharmacology & Therapeutics, 107(4), 871-885.
[2] Nadkarni, P. M., Ohno-Machado, L., & Chapman, W. W. (2011). Natural language processing: an introduction. Journal of the American Medical Informatics Association, 18(5), 544-551.
[3] Miller, E. (1998). An introduction to the resource description framework. Bulletin of the American Society for Information Science and Technology, 25(1), 15-19.
[4] Heflin, J. (2007). An introduction to the owl web ontology language. Lehigh University. National Science Foundation (NSF), 7.
[5] Endert A., Hossain M., Ramakrishnan N., North C., Fiaux P., Andrews C.: The human is the loop: new directions for visual analytics. Journal of Intelligent Information Systems, pp. 1–25 (2014).
[6] Tukey J.W.: Exploratory Data Analysis. Addison-Wesley, Reading MA (1977).