Language Units in Speech Recognition: Does Size Matter?
The article looks into different granularities of language used in the speech recognition task, how they perform, and the pros and cons of using each.
Ekaterina Egorova (BUT), Brno (Czech Republic),
Automatic speech recognition (ASR) is a speech processing task that takes an audio signal as an input and produces the text output of what was said. The success of ASR task is crucial for complex speech-to-speech dialogue applications such as WELCOME, as it is the first step of user input processing: the TCN speaks a phrase which has to be transcribed as correctly as possible for further language analysis modules.
The first decision a designer of an ASR system must make is how to represent speech - a continuous signal in time - in a discrete way? There are several approaches to preparing audio input for processing, but today we will discuss the discretization of the text output. A sentence is too big of an entity to be an output, and also there can be an infinite number of sentences in a language. So, we need to predict a sentence unit-by-unit. How to split a sentence into meaningful units is the focus of this article.
Can we just use words?
If we ask a western person what the most logical unit is to split speech into, they would probably say a word. But how intuitive is a word in reality? A word is usually defined as a single distinct meaningful element of speech or writing, but if we think about this definition some more, we realise it’s not all that helpful in practice. A lot of languages have features that make it difficult to meaningfully split speech into words. For example, if we look at hieroglyphic languages, the whole word is a meaningful unit but so is each of the hieroglyphs that makes it. The same goes for morphemes in western languages: we know for example that the prefix “un-” means not, but is it a word if it’s attached to the following word and also changes a consonant depending on the first letter of the word it’s attached to? On the other hand, prepositions are written separately, but they modify the meaning of the following word rather than have their own. We can be tempted to just go with the simple rule: a word is everything between spaces. But this does not work for example with languages that have ligatures connecting several words together or for synthetic languages that construct words from several different meaningful roots.
But these are all philosophical concerns. A lot of early research in ASR was done on English by western people for whom words were natural units to split speech into. Therefore, optimal or not, prediction of words has a long tradition in speech recognition.
The classical ASR system consists of three components: acoustic model (AM), lexicon and language model (LM). Acoustic model trains statistical representations of speech sounds: phonemes or phonemes in context. The most common representations nowadays are neural network probability estimators [Hin12]. The language model shows how often the word is seen in the current context: for every word there is a probability of it occurring after the previous words. Only text data is needed for training an LM, so it can be trained on much more data than the acoustic model. The lexicon connects AM and LM by providing a correspondence between a word and its pronunciation. These three components are combined in a recognition network through graph composition, so that the lexicon limits the search space of acoustic units in context to only valid words, and LM is allowing for word sequences that are characteristic of the language.
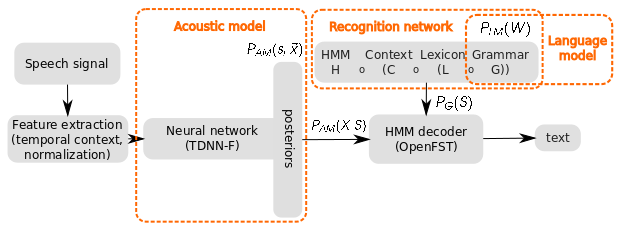
The main benefit of predicting words is that such a system is easily combined with external LMs, trained on nearly endless text data pulled from the internet. Getting text is much easier than collecting acoustic data. The main issue with the word predicting system is the necessity to have a lexicon. A good lexicon requires tens of hours of work by phoneticians, which is of course expensive or not doable at all. Automatically generated lexicons such as [Bis08] can be utilised too but they are as good as the existing profi-made lexicon that they are trained on. Moreover, even if the system has a good lexicon and LM, they are not prepared to deal with out-of-vocabulary words (OOVs) - unseen, new words that always appear in speech. If they were not seen in LM training and the lexicon does not provide a transcription for them, they cannot be produced as the output. In the context of WELCOME, such words are very important, as a lot of TCNs will have to say their names, addresses, names of organisations etc.
So why not use letters?
A letter, or character, is another logical unit to split the speech into. Character-based systems don’t need the dictionary and thus avoid the problem of a limited dictionary altogether and can theoretically generate new unseen words. However, this is not a very widespread approach due to several problems. First, depending on the language, a character can represent widely different sounds, so the system must depend on the context to add necessary information to make the decision. This leads to the second big problem: context span. Classical n-gram language models approximate the word history by just the last few language units, and using more than 5 unit history is not practical due to the resulting graph size. In case of words, 5 previous words is plenty of context, but in case of phonemes, it can be less than one word. In end-to-end systems that utilise long short-term memory (LSTM) neural architecture, history is also getting forgotten with time, so a word in the middle of a sentence can have some information about the first word, but a letter may not.
Is there something in between then?
Can we take the best of the two approaches then? Yes, we can. The most used speech units these days are subword units, and the most popular subword units for speech processing are byte-pair encoding units (BPEs) [Sen16]. They are obtained as a result of an adaptation of a simple data compression technique that iteratively replaces the most frequent pair of bytes in a sequence with a single, unused byte. Instead of merging frequent pairs of bytes, characters or character sequences are iteratively merged to obtain a list of most frequent units. These units can be frequent letters, letter combinations or even commonly-used words. The text is then split into these units and the system is trained to predict these units.
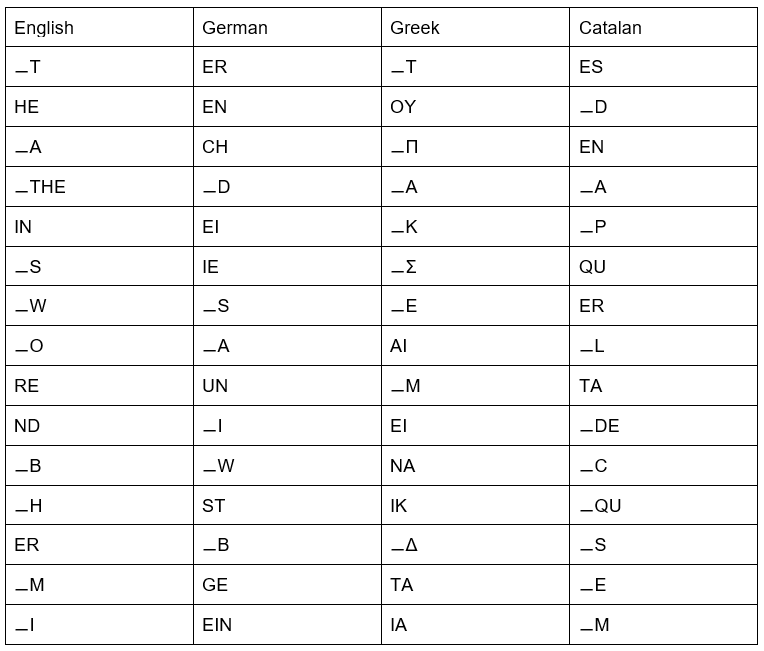
BPEs have bigger granularity than characters and so can preserve a bigger context, but they are still capable of generating new unseen words as the output. If you check Hugging Face, the biggest AI community with state-of-the-art models, you can see that most successful e2e ASR systems nowadays mostly use BPEs as predicted units. Our experiments on Catalan system for WELCOME also support these findings: while the classic word-producing hybrid system reached the word error rate (WER) of 38.6, a BPE-based end-to-end system went down to 25.94 WER.
Is there something even better?
There is constant research going into how to best tokenize speech output. For example, [Zho21] shows how to tokenize words into subword units based not only on character statistics but also on acoustics. Meanwhile, [Cla22] tries to find a way to outperform BPEs with a character-based system. And in the future… who knows? Maybe new architectures will require different language discretization altogether.
Bibliography:
[Bis08] Bisani, Maximilian & Ney, Hermann. (2008). Joint-Sequence Models for Grapheme-to-Phoneme Conversion. Speech Communication. 50. 434-451.
[Cla22] Clark, Jonathan & Garrette, Dan & Turc, Iulia & Wieting, John. (2022). “Canine : Pre-training an Efficient Tokenization-Free Encoder for Language Representation.”, in Transactions of the Association for Computational Linguistics. 10. 73-91.
[Hin12] Geoffrey Hinton, Li Deng, Dong Yu, George Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara Sainath, and Brian Kingsbury, “Deep Neural Networks for Acoustic Modeling in Speech Recognition”, in IEEE Signal Processing Magazine 2012.
[Sen16] Rico Sennrich, Barry Haddow, and Alexandra Birch, “Neural machine translation of rare words with subword units,” in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, Aug. 2016, pp. 1715–1725, Association for Computational Linguistics
[Zho21] Wei Zhou, Mohammad Zeineldeen, Zuoyun Zheng, Ralf Schluter, and Hermann Ney, “Acoustic Data-Driven Subword Modeling for End-to-End Speech Recognition” in Proceedings of Interspeech 2021..